
Le marché de la donnée et les différents secteurs utilisant de la donnée ont montré le besoin d’aller au delà de l’anonymisation de données contenues dans des formats tabulaires simples. Bien entendu, chez Octopize, nos équipes continuent de travailler à l’amélioration de l’anonymisation de données tabulaires mais nos travaux de R&D nous permettent maintenant de gérer d’autres types de données comme :
- les séries temporelles (plus d'infos dans cet article),
- les bases de données relationnelles (plus d'infos sur ces données ici),
- les données de géolocalisation
Intéressons-nous aujourd’hui à ces dernières…
Les données de géolocalisation
Une donnée de géolocalisation est une position généralement définie par deux variables : sa longitude et sa latitude (un point GPS par exemple). On peut trouver ces données dans un jeu de données tabulaire classique (pour définir le domicile d’une personne par exemple) ou sous la forme de plusieurs couples de latitude et longitude (pour définir domicile et lieu de travail d’un individu). Dans certains jeux de données, il s’agit d’une séquence de points de géolocalisation : une trace. Ces points sont souvent associés à des variables de temps représentant l’instant de passage à chacun de ces points. On parle alors de traces horodatées. On peut retrouver de telles traces avec l’historique Google maps d’un individu par exemple.
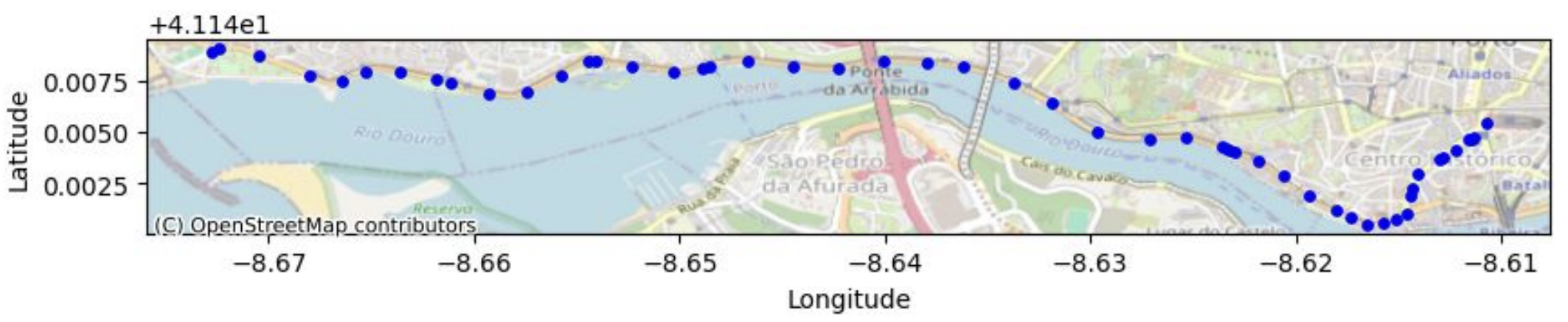
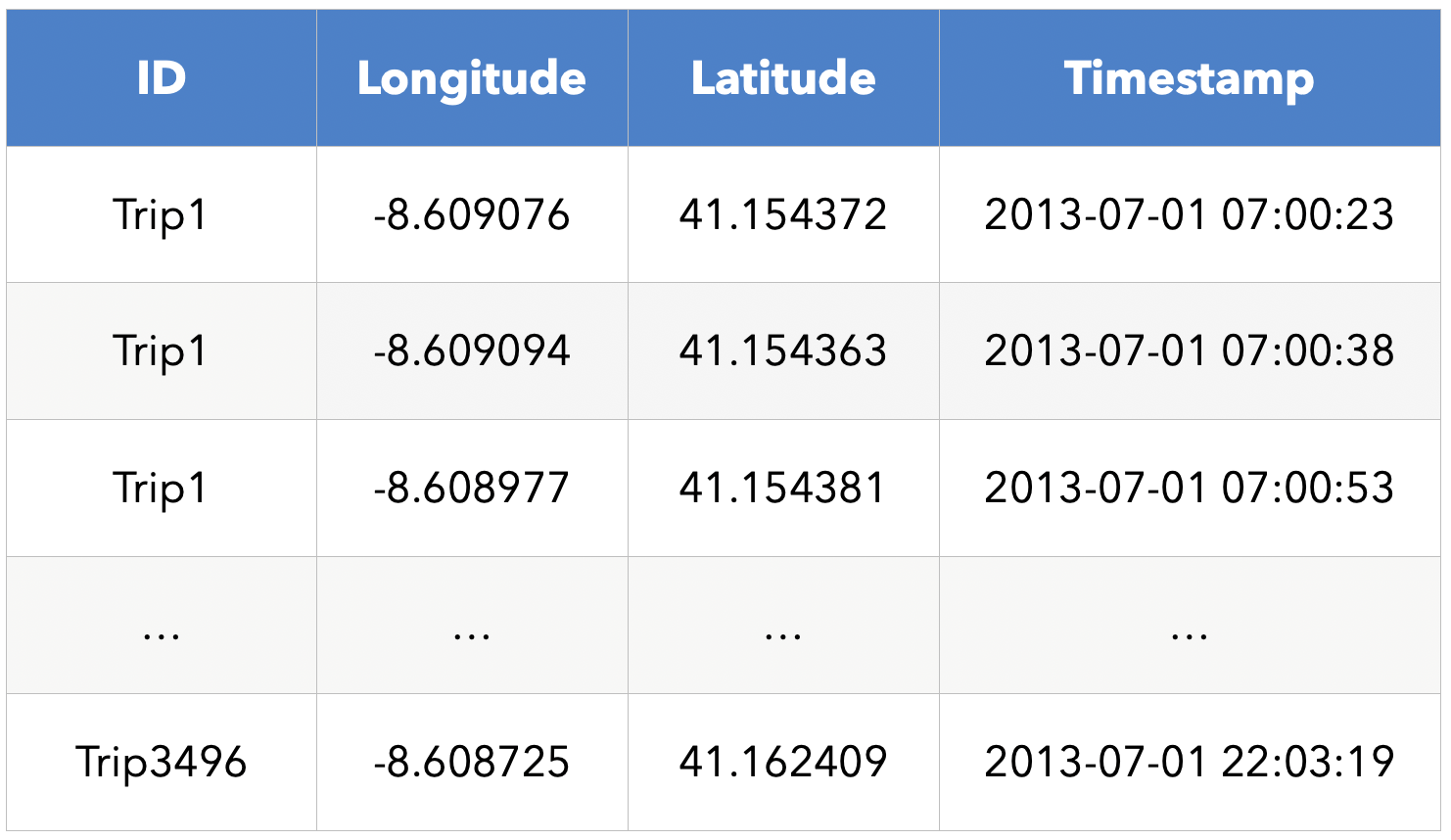
Les traces horodatées contiennent une très grande quantité d’informations qui peut servir à inférer de nombreux détails sensibles sur une personne comme sa religion (visites régulières dans des édifices religieux), son état de santé (visites dans des cliniques spécialisées) ou toute activité qu’il ou elle souhaiterait garder privée. Une étude référence démontre que 4 points d’une traces suffisent à ré-identifier 95% des individus dans un jeu de données tant nos déplacements individuels sont uniques. Le LINC (Laboratoire d’Innovation Numérique de la CNIL) s’est également penché sur le sujet et a démontré qu’il était très simple de remonter jusqu’à des individus à partir de données pseudonymisées mises à disposition par des courtiers en données (lien de l'étude ici). Cela met en évidence la difficulté de l’anonymisation de traces complètes comportant très souvent bien plus que 4 points…
Anonymisation de données de géolocalisation
Chez Octopize, nous acceptons ce défi et travaillons sur 3 axes principaux :
- l’anonymisation de données minimisées (disponible actuellement),
- l’évaluation du respect de la vie privée associée à un jeu de données ayant reçu un traitement d’anonymisation ou s’en rapprochant (disponible actuellement)
- et enfin l’anonymisation de traces complètes (travaux en cours).
Minimisation et anonymisation
Le principe de minimisation préconise de récolter et conserver seulement les variables utiles à un usage particulier. En plus d’être un principe clé dans le domaine de la protection des données, minimiser les données rends possible leur anonymisation et la conservation de l’utilité nécessaire à l’usage. Par exemple, une collectivité souhaitant analyser des flux de déplacements n’a pas besoin d’utiliser les traces complètes pour cela. Utiliser seulement les points de départ et d’origine des trajets le permet et leur anonymisation permet de conserver ces données sans limites de temps.
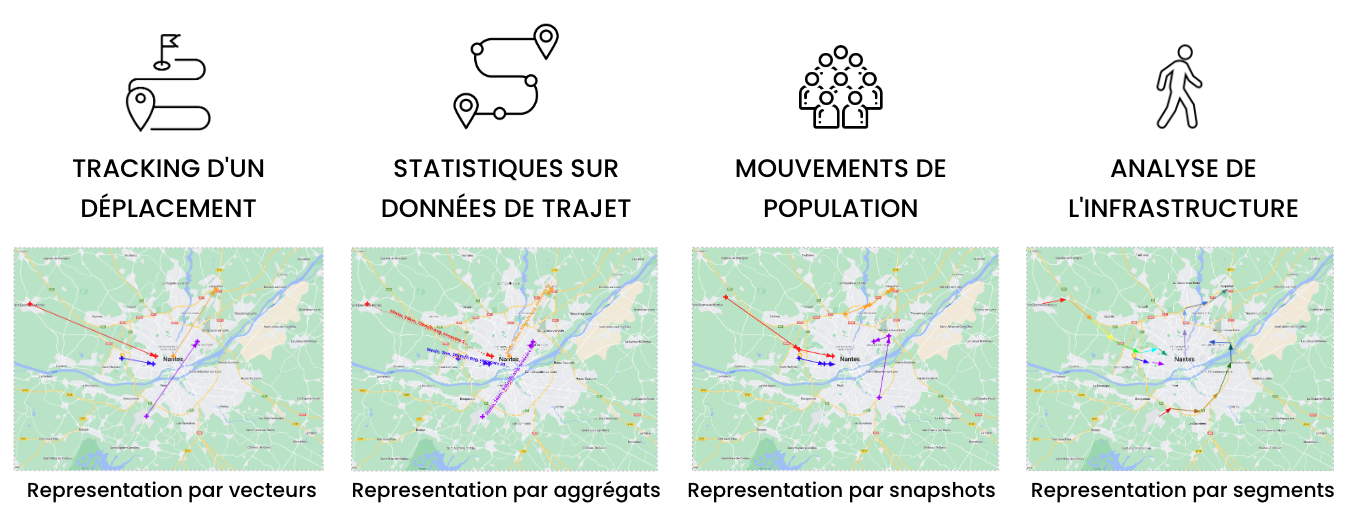
Suivant cette approche de minimisation, nous suggérons 4 représentations qui sont compatibles avec la méthode avatar :
- Vecteurs : seuls les points d’origine et de destination sont extraits avant d’être anonymisés. Les vecteurs permettent notamment de mener des analyses sur les pratiques de transport en commun et de covoiturage.
- Agrégats : des statistiques sur chaque trajets sont extraites (exemples : longueur, vitesse moyenne, nombre d’arrêts, temps passé dans une plage de vitesse etc…). Ces agrégats sont utilisés à des fins d’analyse comportementale d’utilisateurs ainsi que dans des contextes de maintenance prédictive.
- Snapshots : seule la localisation des individus à un instant précis est conservée. Plusieurs snapshots successifs peuvent être générés et anonymisés mais une trace ne peut pas être reconstituée à partir de ces snapshots. L’utilisation de snapshots a fait ses preuves dans des études d’impact pour comprendre l’attractivité d’un événement ou les conséquences de travaux de voirie.
- Segments : les trajets sont divisés et les identifiants des trajets et véhicules sont enlevés. Une fois anonymisés, il est impossible de reconstruire les trajets. Ce type de représentation est adapté aux études portant sur l’analyse des infrastructures et des conditions de circulation.
Notons que d’autres représentations minimisant la donnée et compatibles avec l’anonymisation peuvent être considérées. Aussi il est possible de mélanger des concepts provenant de plusieurs représentations. Par exemple, pour certains cas d’usage, il peut être interessant de conserver les origines et destinations des trajets ainsi que les statistiques agrégées de ces trajets (mélange de vecteurs et d’agrégats).
Évaluation de la privacy de méthodes d’anonymisation traitant des traces complètes
Les approches minimisant les données peuvent traiter beaucoup de cas d’usage mais il reste des contextes pour lesquels la conservation de la donnée presque brute (sous formes de traces complètes ou quasi-complètes) est nécessaire. L’état de l’art (académique et industriel) sur le sujet est très concis et à l’heure actuelle, il n’existe pas de méthode capable d’anonymiser ce genre de données de manière fiable mais certaines entreprises (Octopize y compris) se penchent sur le sujet.
Afin d’évaluer le résultat des traitements qui peuvent être appliqués sur des traces complètes, nous avons récemment mis à disposition via notre outil une fonctionnalité permettant de mesurer la privacy vis-à-vis des 3 critères du RGPD. Cet outil d'évaluation de la privacy prend en entrée des données originales et des données traitées et génère un rapport de privacy permettant aux équipes travaillant sur le sujet d’itérer.
Anonymisation de traces complètes
En collaboration avec le Laboratoire des Sciences du Numérique de Nantes (LS2N) de l’École Centrale Nantes dans le contexte d’une thèse CIFRE, nous travaillons sur l’anonymisation de traces complètes. Ces travaux commencent à porter leurs fruits.
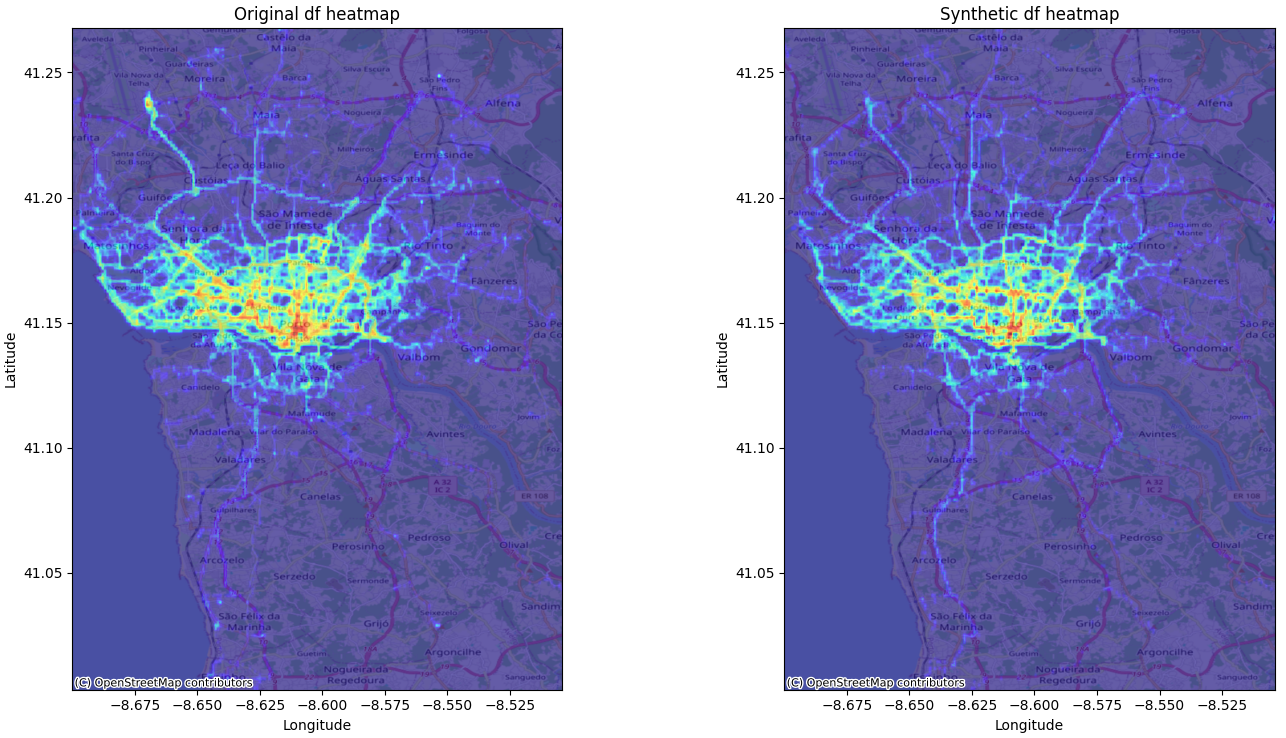
Ci-dessous, nous illustrons ces propos avec un exemple de génération de traces synthétiques (à droite) à partir d’un tirage d’une modélisation statistique du jeu de donnée original (à gauche). La similitude des cartes de chaleur calculée sur les données originales et sur les données synthétiques montre la similarité statistique des deux jeux de données, prouvant la pertinence de l’utilisation du jeu de donnée synthétique pour des usages analytiques.
Tout en continuant d’améliorer la synthétisation des traces à partir des paramètres, nous travaillons désormais également sur l’anonymisation de ces paramètres avec pour but la génération de traces horodatées réellement anonymes. Leur caractère anonyme sera évalué grâce à notre brique de privacy assessment.
Ces travaux s’intègrent également dans notre engagement avec l’Agence de l’Innovation dans les Transports (AIT) qui nous accompagne dans le cadre du programme Propulse pour lequel nous somme lauréats 2024.


